
最近这段时间,我同时在用好几个 AI 编程工具:Claude Code、Cursor、Codex、Gemini CLI、Qwen Code……每个都有自己顺手的地方,但配置也各管各的。
一开始只是觉得有点麻烦,后来发现这个事情会慢慢变成一个小坑:我在 Claude Code 里加了一个好用的 MCP,Cursor 没有;我在 Codex 里改了 AGENTS.md,Claude Code 的 CLAUDE.md 又没同步;某个 skill 在一个工具里是新版,另一个工具里还是旧版。
于是就做了 Plexus。
它想解决的事情很简单:
只配置一次,然后同步到所有你常用的 AI Agent。
先看效果
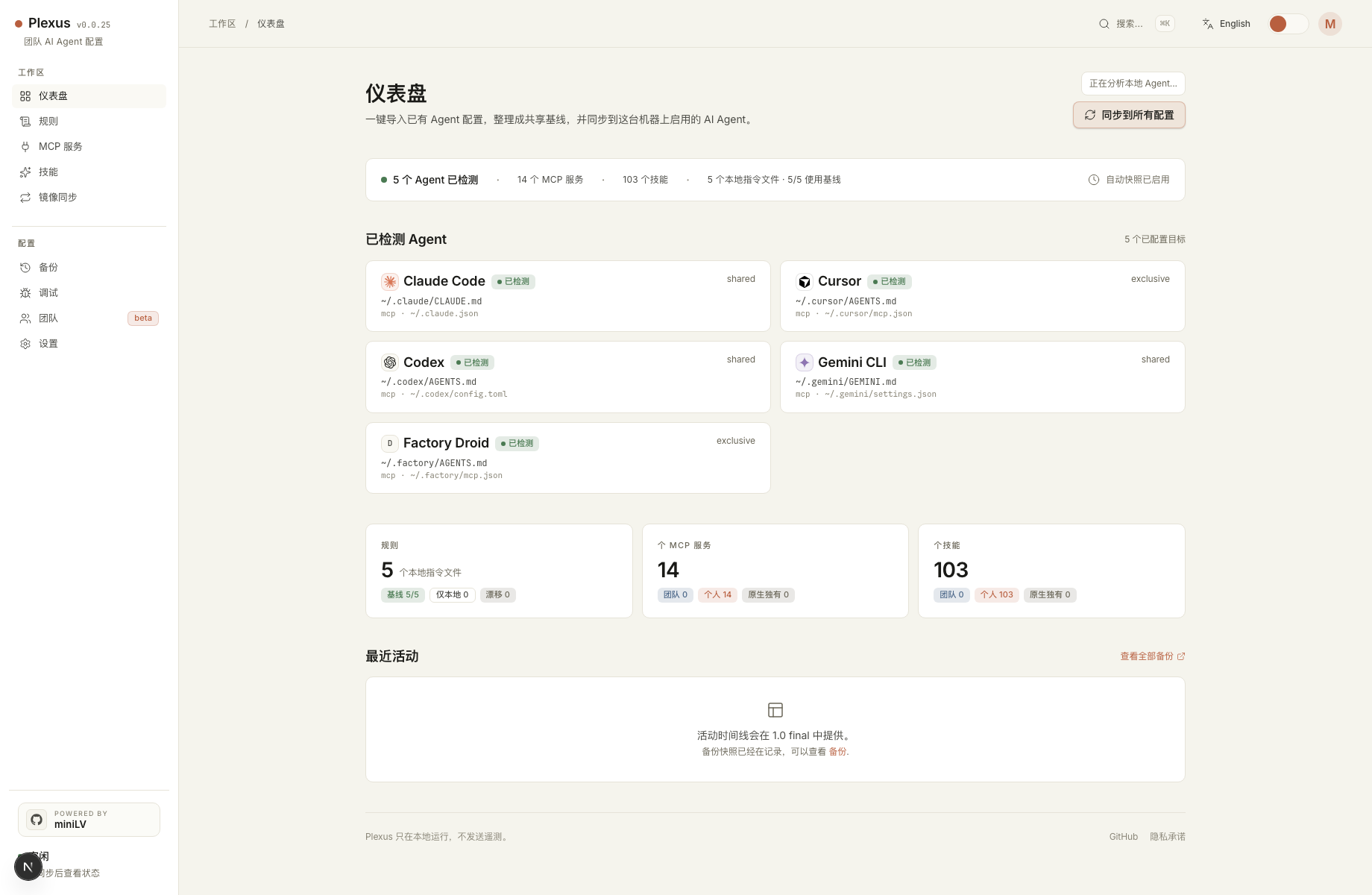
Plexus 会扫描你本机已经配置过的 AI Agent,然后把 Rules、MCP Servers、Skills 展示在一个 dashboard 里。
目前主要支持:
- Claude Code
- Cursor
- Codex
- Gemini CLI
- Qwen Code
- Factory Droid
如果你的工具还不在内置列表里,也可以在 Settings -> Agent Catalog -> Add agent 里手动新增一个 instruction file。这个模式比较轻量,主要是先让 Plexus 帮你查看、编辑和备份这个文件,MCP / Skills 的完整 adapter 后面再慢慢补。
它到底解决什么问题?
假设你现在同时使用 Claude Code 和 Cursor。
Claude Code 读的是:
~/.claude/CLAUDE.md
~/.claude.json
~/.claude/skills/
Cursor 读的是:
~/.cursor/AGENTS.md
~/.cursor/mcp.json
~/.cursor/commands/
Codex 又是另一套:
~/.codex/AGENTS.md
~/.codex/config.toml
~/.codex/skills/
如果你只是偶尔改一次配置,手动复制也不是不能忍。但一旦你开始认真维护这些东西,比如:
- 维护一份通用的 agent 行为规则
- 给所有工具加同一个 MCP Server
- 把自己常用的 skills 分发到不同 agent
- 给团队成员同步一套默认配置
那手动复制就会变得很烦,而且很容易忘记自己到底改过哪里。
Plexus 的思路是:不要让每个工具各自漂移。先把配置整理到一个本地统一源里,再投射回每个工具自己的原生路径。
最短使用路径
目前 Plexus 还是 alpha 阶段,可以先从源码启动:
git clone https://github.com/miniLV/Plexus.git
cd Plexus
npm ci
npm run dev
然后打开:
http://localhost:7777
第一次使用时,可以直接点 Dashboard 右上角的 Share config everywhere。
它会做三件事:
- 扫描本机已经存在的 AI Agent 配置。
- 把已有 Rules、MCP Servers 和 Skills 导入到 Plexus 的本地 store。
- 再同步到所有启用的 Agent。
如果多个 Agent 里已经有同名配置,但是内容不同,Plexus 会让你选一个 Primary Agent。比如你觉得 Codex 里的配置最完整,就可以选择 Codex 作为主来源。
这点很重要。因为“一键同步”最怕的不是没同步,而是不知道谁覆盖了谁。
Rules:一份规则同步到所有工具
比如 Claude Code 常用 CLAUDE.md,Codex / Cursor 常用 AGENTS.md,Gemini CLI 可能是 GEMINI.md。
它们本质上都是 instruction file,只是文件名和路径不同。
Plexus 会把共享规则放在:
~/.config/plexus/personal/rules/global.md
然后同步到各个工具的原生位置:
~/.claude/CLAUDE.md
~/.codex/AGENTS.md
~/.cursor/AGENTS.md
~/.gemini/GEMINI.md
这样每个工具仍然读取自己熟悉的文件名,但背后可以指向同一份规则。
如果后悔了,也可以在界面里 detach,把某个 Agent 的规则文件重新变回本地独立文件。
MCP:为什么不能全部软链接?
这个地方是 Plexus 里最需要小心的部分。
有些工具的 MCP 文件是单用途文件,比如 Cursor 的:
~/.cursor/mcp.json
这种文件基本只放 MCP 配置,Plexus 可以比较放心地托管它:生成一份 cache 文件,然后让 Cursor 的 MCP 文件通过 symlink 指过去。
但有些工具不是这样。
比如 Claude Code 的配置文件可能是一个更大的 JSON,里面除了 MCP,还可能有 auth、history、profile、model settings 等等。Codex 的 config.toml 也类似,里面不一定只有 MCP。
这种文件就不能粗暴覆盖,也不适合直接软链接。
所以 Plexus 对 MCP 用的是 hybrid 策略:
| 文件类型 | 处理方式 |
|---|---|
| 专用 MCP 文件 | cache symlink / copy |
| 共享配置文件 | partial-write,只改 MCP section |
也就是说,对于共享配置文件,Plexus 只改自己负责的 mcpServers 或 mcp_servers 那一段,其他内容尽量保持原样。
这也是为什么它不是简单写一个脚本 cp config A config B 就完事。
Skills:最适合用目录软链接
Skill 通常本来就是一个目录,里面有一个 SKILL.md,再加一些脚本、参考资料或模板。
所以它比 MCP 更适合共享。
Plexus 会把 skill 放在:
~/.config/plexus/personal/skills/<id>/SKILL.md
再同步到不同工具的目录:
~/.claude/skills/<id>
~/.codex/skills/<id>
~/.factory/skills/<id>
对于 Cursor 这种更偏 command 形态的工具,也可以投射到它自己的 commands 目录。
这里优先用目录级 symlink。如果系统不支持 symlink,或者目标环境不允许,就 fallback 到 copy。
一张图看懂架构

Plexus 的核心分成三段:
- Native import:从已有 Agent 原生配置里导入。
- Canonical store:把配置整理到
~/.config/plexus/。 - Native projection:再投射回每个 Agent 自己会读取的位置。
中间的 canonical store 大概长这样:
~/.config/plexus/
├── config.yaml
├── team/
├── personal/
│ ├── mcp/servers.yaml
│ ├── rules/global.md
│ └── skills/<id>/SKILL.md
├── .cache/mcp/
└── backups/
这里分了两层:
team/:团队共享配置,比如统一的 rules、skills、MCP baseline。personal/:个人配置,比如自己的 token、本机路径、私有 MCP。
如果 team 和 personal 里有同 ID 的配置,personal 会覆盖 team。这个逻辑很符合直觉:团队给默认值,个人做覆盖。
Team Config:团队里会更有用
单人使用 Plexus,主要是减少重复配置。
但我觉得它更有意思的地方在团队场景。
比如团队可以维护一个配置仓库:
agent-primer/
├── rules/global.md
├── skills/code-review/SKILL.md
├── skills/architecture-designer/SKILL.md
└── mcp/servers.yaml
每个人把这个 repo 作为 team layer 拉下来:
plexus join https://github.com/miniLV/agent-primer.git
plexus pull
plexus sync
这样团队新增一个 code-review skill,大家只需要 pull + sync,就能同步到 Claude Code、Cursor、Codex 等工具里。
当然,带 token 的东西不要直接放 team repo。比较好的做法是:team repo 里放 placeholder 和默认结构,个人在 personal/ 层补自己的 token 或本机路径。
安全和回滚
做这种工具,最怕一件事:帮用户同步配置,结果把原来的配置搞没了。
所以 Plexus 在写入 Agent 原生文件前,会先做 snapshot:
~/.config/plexus/backups/
如果目标位置已经有真实文件或目录挡住了 symlink,Plexus 不会直接覆盖,而是会移动到 collision 备份区:
~/.config/plexus/backups/_collisions/
Backups 页面里可以看到这些 snapshot,也可以恢复。
这个设计不花哨,但很必要。因为它管理的不是 demo 数据,而是你真实在用的 AI 工具配置。
适合谁?
如果你只用一个 AI 编程工具,而且配置也很少,那 Plexus 可能暂时没必要。
但如果你有这些情况,它会比较适合:
- 同时用 Claude Code、Cursor、Codex 等多个工具
- 经常维护 MCP Server
- 有自己的 agent rules / skills
- 希望团队共享一套 AI Agent 配置
- 想知道每次同步到底改了哪些文件
- 想要同步前自动备份,出问题能恢复
简单说,如果你已经开始认真维护 AI Agent 配置,那就值得试一下。
写在最后
Plexus 不是一个 runtime engine,不负责运行 MCP,也不替代 Claude Code、Cursor 或 Codex。
它更像一个本地配置中枢:把散落在不同工具里的配置收回来,整理成一份基线,再用尽量安全的方式同步出去。
这件事听起来不大,但每天在几个 AI 工具之间切来切去的人,应该会懂这种痛。
目前项目还在 alpha 阶段,很多地方还会继续迭代,比如更完整的 team flow、更多 agent adapter、更好的 diff / conflict UI,以及更方便的安装方式。
如果你也同时用多个 AI 编程工具,欢迎试试看。
项目地址:Plexus
团队配置示例:agent-primer
觉得有用的话,欢迎 Star ⭐